Abstract
DNN기반으로 user-item interaction을 인코딩 하는게 CF 성능 높이지만, latent features 무시하고 sparse 데이터에 취약하다.
이 논문에서는 영화 추천을 위해 GAN-based model을 통합한 novel knowledge-enhanced deep recommendation framework(KTGAN)를 제안
Introduction
- CF-based method 같은 경우는 별점, 리뷰, 구매기록과 같은 observed user-item interaction을 기반으로 추론하기 때문에 data sparsity에 문제를 겪음
- 그래서 기록에 없는(unobserved) interaction을 학습하기 힘든 cold start 문제를 겪음
- DL-based model의 성능이 좋아 최근에 사용하기도 함
- 하지만, DL에도 문제는 있음
1. observed user-item interaction을 기반으로 함
2. single type의 임베딩을 함(knowledge 임베딩 아님) -> 사용자의 특징을 충분히 담아낼 수 없음
(single type: clicked, watched, ...)
3. 아이템 추천에 IRGAN이 잘 되는 것을 증명 했지만, random으로 initialize된 모델 사용하기 때문에 pre-training을 피할 수 없음
Our Framework!
: random initialize 대신에!
- user/movie representations를 풍부하게 하기 위해 다양한 피처 벡터들을 통합한다.
- Knowledge Graphs로부터 knowledge embeddings(ke)
e.x) movie's ke: entity embedding과 context embedding의 결합
user's k.e: his/her favorite embedding 평균(그냥 평준화 한다는 뜻??)
- Tag corpus로부터 tag embedding(te)
(te: tag들 사이의 co-occurrence를 encode)
=> 그래서! knowledge embeddings에 tag embeddings를 추가하는 것은 효과적이고 실험을 통해 증명도 해 보았다!!!
main contribution
1. randomly initailize하기 보다는 다른 source들로부터 다양한 의미있는 임베딩을 통합한다. 그리고 이러한 sparse한 경우에도 추천이 잘 되는 임베딩으로 GAN-based model에 적용!
2. 좋은 성능을 보여주었고, 다양한 의미있는 임베딩의 통합의 필요성을 보여줌
Solution
A. The Framework
- 다른 source들로부터 다양한 임베딩을 합침
- user/movie representations를 generator와 discriminator에 feed
- top-N movie recommendation 추출

phase1.
Knowledge Embedding(ke)
- movie's feature embeddings 만들기 위해 KG의 knowledge 불러옴
- entity embedding(ee)
- 영화의 제목을 지칭
- context embedding(ce)
- 영화 entity 노드의 주변 노드는 영화의 attribute라 부름(directors, actors, genres)
- 영화의 context embedding(ce)은 attribute embedding의 weighted sum
- ee + ce = ke(knowledge embedding)
- entity embedding(ee)
- user's feature embeddings
- user의 favorite movies의 knowledge embeddings의 평균
Tag Embedding(te)
- dataset에서 모든 users/movies에 대한 tags도 있음(genres, directors, countries와 같은)
- tag를 벡터화하기 위해 word2vec 사용
- 모든 tag vectors의 평균
phase2.
- user/movie representation을 generator G와 discriminator D로 보냄(IRGAN 기반으로 설계됨)
- 일반적인 IRGAN에서는 G와 D를 랜덤으로 초기화하고, pre-training 시키는데 이게 너무 비용이 큼
- 이 모델은 랜덤으로 들어오는 게 아니라 te, ke의 concat으로 들어오기 때문에 더 잘 나타낼 수 있음
- training-set(observed user-movie interation)은 TP샘플을 라벨링 하기 위해 두 모델에 적용됨
- output은 top-N movie recommendation
- y_um은 candidate movie m이 user u에 의해 선호 될 것이라는 표현
B. Distilling Movie's Knowledge Embeddings
먼저, CN-DBpedia에서 관련 있는 knowledge를 추출해 현재 dataset에 포함해 sub-KG 구성
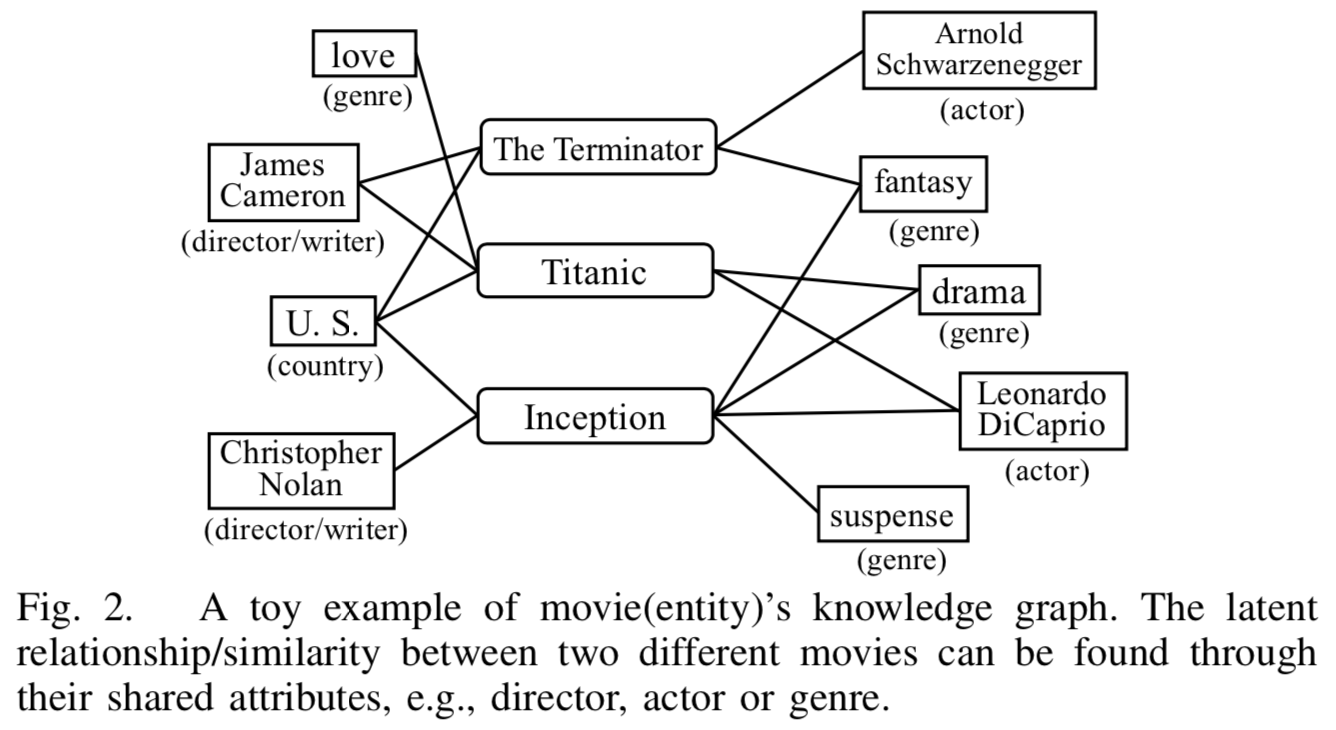
movie's KG는 heterogeneous information network(HIN)로 이루어짐
-> 영화 사이의 관계 파악 가능
-> 두 영화 사이에 많은 attribute node와 관계가 있다면 많이 유사하다는 뜻
contextual information(movie's attributes)을 사용하는 것은 의미론적/논리적 관계가 담겨 있음
그래서, 사용하는 것은 영화의 특성을 나타내는데 좋은 요소임
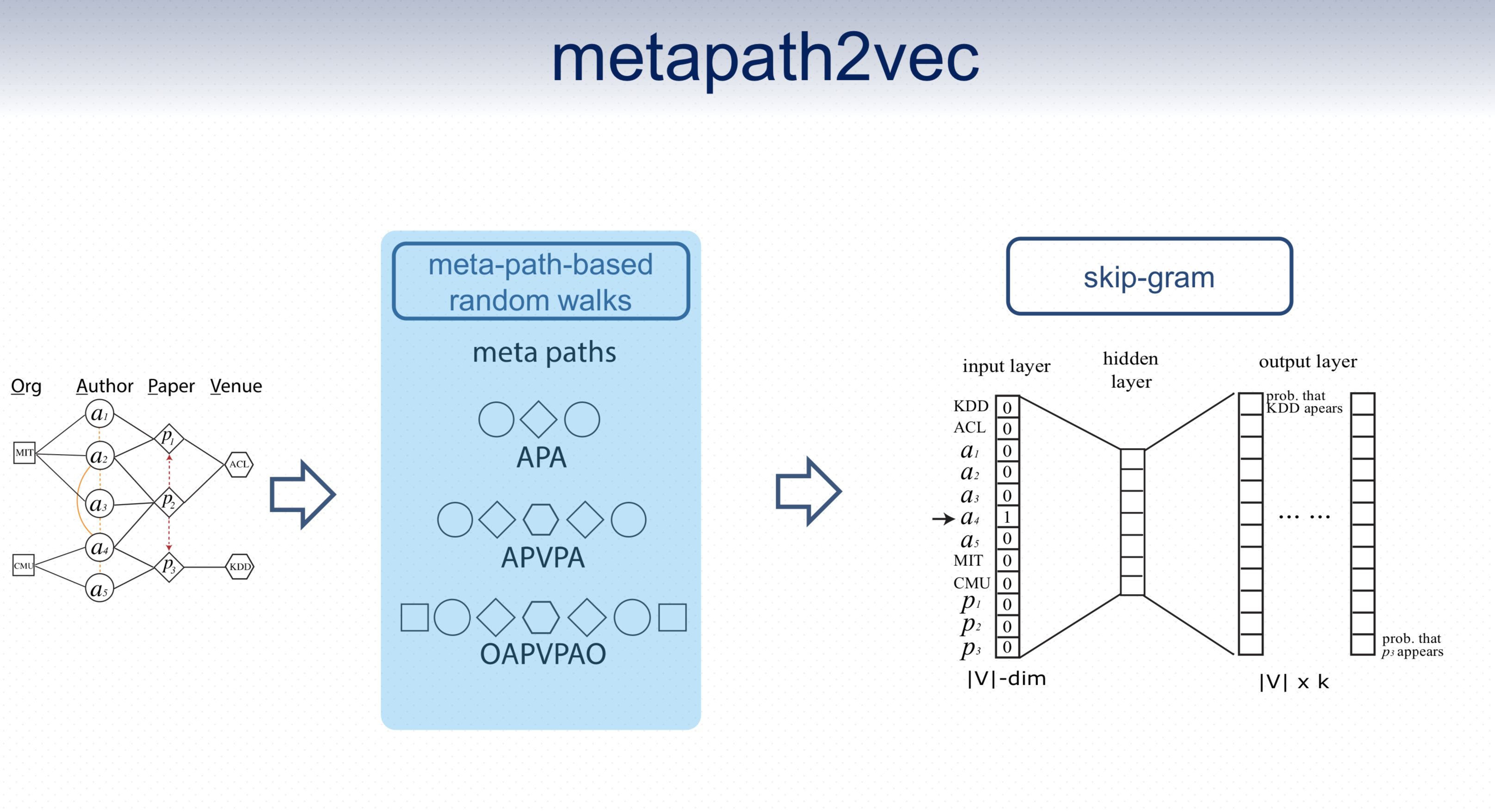
attribute관계를 담기 위해 Metapath2Vec을 사용 (당시 최신 논문에서 HIN embedding에 성능이 좋았다고 함)
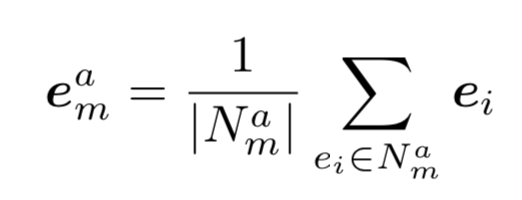
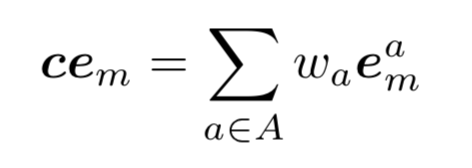
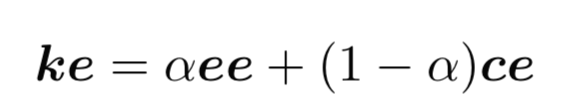
C. Learning Optimal Representations by GAN-based Models
generator와 discriminator가 training을 통해 최적의 value 찾아냄
Generator G는 조건부 확률에 따라 candidate pool에서 가장 좋아할 것 같은 영화 generate
Discriminator D는 확률에 따라 진짜 관련 있는 user-movie 쌍 분별해 냄(binary classifier)
G와 D는 계속 경쟁함
G는 D를 혼란스럽게 할 만큼 그럴듯하게 보이기, D는 G가 진짜인지 가짜인지 분별해내기

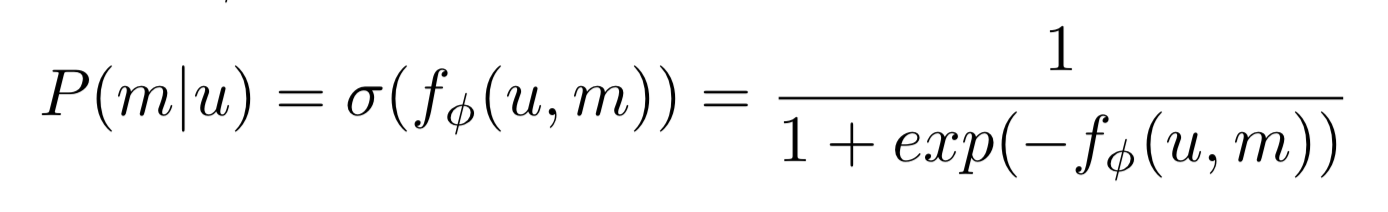
discriminator's objective
- optimal P(m|u,r)를 찾아내서 log-likelihood를 최대화
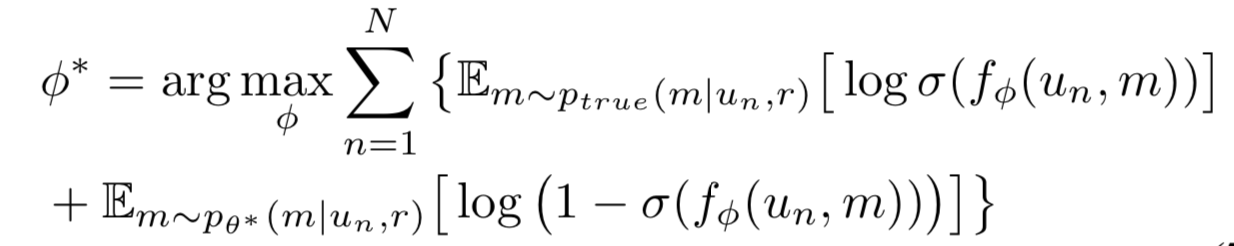
generator's objective
- P_theta를 P_true라는 기존 조건부 확률에 fit하게 만들기
- minimization은 gradient descent로 해결할 수 없어서 policy gradient 사용
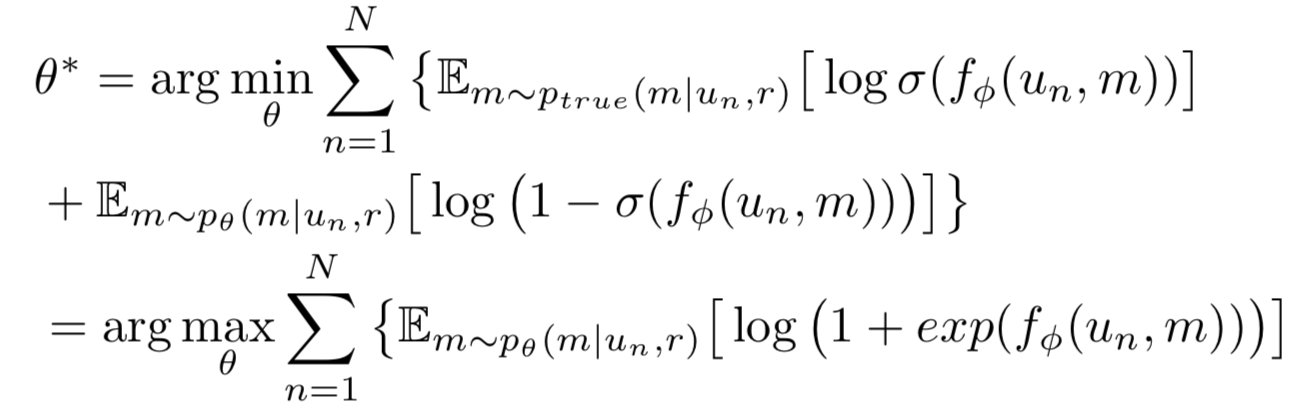
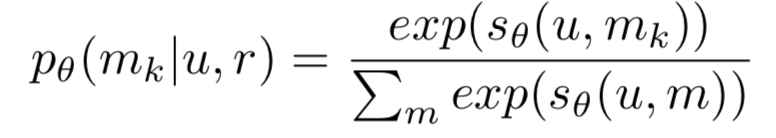
score function
- 처음엔 phase 1에서 나온 값을 적용
- 트레이닝 끝엔 optimal e_u, e_m
- user가 movie를 선택할 수 있는 기회를 정량화 시킨 수식
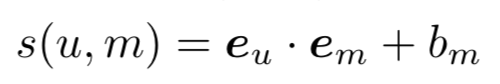
Experiment Settings
1) Dataset
- Douban
- movies: 42000
- users: 5000
- movie/user interaction(rating scores)
- movie/user tags: 89909
- CN-DBpedia
- attributes of movies
2) Sample Division
- user/movie representations이 KG와 tag 기반으로 하기 때문에, interation을 가지고 할 때의 cold start 문제 해결 가능
- 특정 비율에 따라 랜덤하게 나눔
- training set(observed pairs)
- test set(unobserved pairs)
3) Evaluation Metrics
- top-N recommendation 평가를 위해 3개의 metrics 사용
- Precision
- Average Precision
- Normalized Discounted Cumulative Gain
4) Baselines
- COS
- NFM
- NCF
- IRGAN
- KGAN
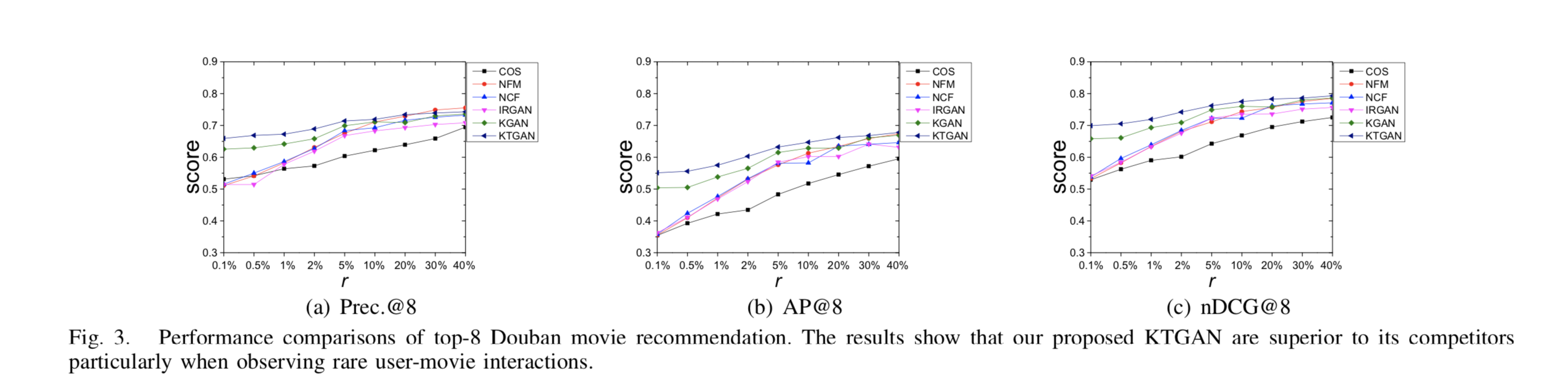
Experiment Results
Discussion
- user/movie의 knowledge embedding & tag embedding의 뛰어난 성능(observed user/movie interaction보다)
- cold start 문제 완화시킴
- KGAN보다 우세한 점
- tag embeddings을 사용함으로써 더 많은 정보를 공급 받아 더 잘 표현 가능
- r(sparsity)이 작을때 차이를 더 잘 나타냄
- IRGAN은 randomly initialize하기 때문에 optimal과는 거리가 멀다
+++
미분이 불가능한 문제를 미분이 가능하도록 풀기 위해 GAN을 사용
(GAN-loss 가지고 다님)




댓글