Abstract
: 기존에 주로 사용해온 임베딩, MLP 패러다임은 raw feature를 낮은 차원의 벡터로 임베딩해서 사용자의 행동 시퀀스를 무시하고 다른 feature들과 연결시킨다. 본 논문에서는 사용자의 행동 시퀀스를 중요시 여기고, 그 시퀀셜한 신호를 찾아내기 위해 powerful Transformer 모델을 사용한다. 결과적으로 위 모델을 사용했을 때 실험 결과도 우수하게 나왔고, CTR에도 다른 베이스라인과 비교했을 때 개선사항이 있었다.
Introduction
[15] 논문에서 다룬것 처럼, 알리바바에서 추천시스템은 두 단계 파이프라인이 있다.
첫 번째는 'match'
-> 유저가 선택해왔던 아이템에 따라 유사 아이템들을 제시하는 것이고
두 번째는 'rank'
-> 사용자가 아이템을 클릭하는 확률을 예측해서 제시해줄만한 아이템을 수백만개 갖고 있는 것
rank stage에서 사용자에 클릭에 의한 행동 시퀀스 같은 CTR(Click Through Rate)을 예측하는 모델(한 유저가 타겟 아이템을 클릭하는 확률)
(논문 저자가 블로그에 기술한 내용 참고하면 이해 더 쉬울 듯!)
https://www.alibabacloud.com/blog/how-does-the-recommendation-system-work-on-tmall_595335
How Does the Recommendation System Work on Tmall?
Alibaba algorithm engineer explains how the Tmall homepage recommendation system works, discussing everything from knowledge graphs to all kinds of neural networks.
www.alibabacloud.com


1. Embedding layer
"Other Features"
- 모든 인풋을 고정된 낮은 차원 벡터로 임베딩한다
- transformer로 행동 시퀀스를 모델링 함
- User Profile/Item/Context/Cross Features 사용

- d0은 차원 크기
"Sequence Item Features"
- 타겟 아이템을 포함하여 행동 시퀀스에서 각 아이템을 위한 임베딩을 얻는다
- 두 종류의 feature를 사용(Positional Feature, Sequence Item Features)
- 아이템은 feature가 너무 많아서 전부 사용하기엔 비용이 많이 든다.
- item_id, category_id 두 개 만으로도 좋은 성능 낼 수 있음
- 두 feature를 concatenate해서 Wv 행렬을 만든다.

- dv는 임베딩의 차원 크기이고, |V|는 아이템의 수이다
Positional Embedding
- 사용자의 행동 시퀀스에는 순서가 존재함
- 즉, 시간의 순서/흐름이 중요한 경우에 사용
- 추천이 이루어지는 시간 - 유저가 클릭한 시간(아래 수식)

- 그래서 낮은 차원의 벡터로 영사되기 전에 각 아이템의 인풋 feature로 position을 추가함
2. Transformer layer
1. Self-attention layer
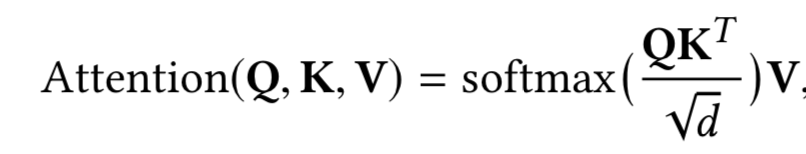
Q: query
K: keys
V: values
아이템의 임베딩을 인풋으로 갖고, linear projection을 통해 세 개의 행렬로 변환한다. 그리고 어텐션 레이어로 feed-forward 진행
*multi-head attention 사용(??? 이게 몬지 모르겠어서 더 찾아보기!!!)
2. Point-wise Feed-Forward Networks(FFN)
비선형을 위한 모델을 향상시키기 위해 추가
오버피팅을 피하고 의미있는 feature를 학습하기 위해 dropout(self-attention)과 LeakyReLU(FFN)를 사용

3. Stacking the self-attention blocks
self-attention 후에 아이템 시퀀스간 복잡한 관계를 더 잘 모델링하기 위해 모든 아이템의 임베딩을 합친다.
3. Loss 구하는 식

(정리 진행중)




댓글