논문 링크
http://www.personal.psu.edu/~gjz5038/paper/www2018_reinforceRec/www2018_reinforceRec.pdf
딥 러닝 모델을 이용해 뉴스 추천을 하는 데는 세 가지 취약점이 있다.
- 첫 번째는 뉴스를 추천하는 데 다이내믹한 변화로 인해 다루기 어렵다는 점이다. 기사가 발행되고 마지막 사람이 볼 때까지의 시간은 4.1 시간으로 터무늬없이 짧기 때문에 당장 하루만 지나도 시대에 뒤떨어져버린다. 그리고 사용자의 흥미가 시간에 따라 변화한다. 어느 날은 정치 기사를 많이 보고 다른 어느 날은 연예 기사를 많이 보기 때문에 주기적으로 모델을 업데이트 해줘야 한다. 하지만 기존 모델들은 현재 reward만 최대화하려고 하기 때문에 위와 같은 문제가 생기는 것이고, 현재의 추천이 미래에 어떤 결과를 낳을 지에 대한 고려는 하지 않는다.(이 부분에서 사용자에 취향이란게 존재할까? 라는 생각이 들었지만, 'G-dragon 결혼!'과 같이 이목을 끄는 핫이슈 기사에도 반응하는사람 반응하지 않는 사람이 존재할 것이다. 또한, 정치에 관심 있는 사용자들은 딱히 이슈가 없어도 습관적으로 기사를 보는 패턴도 존재할 것이다.)
- 두 번째는 기존 추천시스템 논문들은 사용자의 feedback으로 오직 click/no click 레이블만 고려한다는 점이다. 이 경우에는 어떤 종류의 기사에 어느 정도의 시간을 할애하는지에 대한 정보를 알 수 없고 하다못해 사용자가 실수로 잘못 누른 기사와 1시간 가량을 쓴 기사에 대한 reward는 같다는 문제가 생긴다.
- 세 번째는 기존 추천시스템 논문들은 사용자에게 유사 아이템을 추천하려는 경향이 있는데, 이러한 경향은 유사 주제에 대한 사용자의 흥미를 떨어트린다는 점이다. 본 논문 작성 당시 강화학습 방법은 입실론 그리디나 UCB(Upper Confidence Bound)를 사용해왔다. 입실론 그리디의 경우는 관계 없는 아이템을 추천할 수도 있고, UCB는 기존 아이템에 대한 데이터가 없다면 reward 추정에 비교적 정확성을 얻기 힘들다는 아쉬운 점이 있었다.(cold start 문제를 지칭하는 것 같음)
그래서 본 논문에서는!
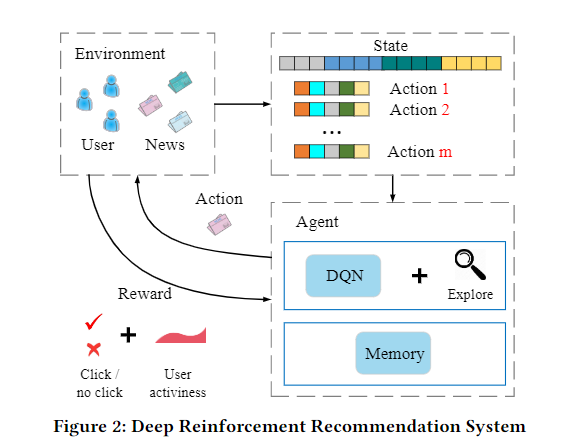
- 'DQN(Deep Q-Learning)' 프레임워크를 사용해 현재와 미래 reward를 동시에 고려한다.
- future reward를 고려하기 때문에 MAB(Multi Armed Bandit)과는 다르다.
- 기존 click/no click reward 방식에 'activeness'라는 사용자가 한 번의 추천을 받은 후 다시 메인에 돌아오는 빈도를 고려하는 feedback을 추가한다.
- 사용자의 continuous state representation & multi-layer DQN의 입력값으로 쓰이는 News list(items)의 continuous action representation을 사용하기 때문에 사용자 로그를 사용하는 MDP와는 다르다.
- 추천에 다양성을 개선시킬 수 있는 'Dueling Bandit Gradient Descent'라는 exploration 전략을 적용한다.

모델은 크게 offline, online 방식으로 나눌 수 있다.
offline 방식은 사전에 학습 시켜서 가중치를 적용 해놓은 모델이고, online 방식은 reward가 들어오면 순차적으로 학습시켜서 가중치를 업데이트하는 과정을 지칭한다.(본 논문에서는 기존 데이터로 사전 학습 시키고-offline, 진짜 유저의 실시간 feedback을 토대로 학습해나가는-online 모델을 사용한다.)
- Offline Part에서 user-news click logs로 학습해서 4종류(News, User, User news, Context)의 feature를 추출했다.
- 사용자가 click/no click한 로그 정보를 토대로 학습시킴
- offline part는 static한 dataset만 다룬다. 그래서 exploration하는 데 제약이 있을 뿐 아니라 시간에 따른 user activeness도 파악하기 힘들다.
- Online Part(실시간)
- PUSH: agent G가 입력 값으로 current user의 features와 news candidates(현재 추천 받은 리스트와 유사도가 높은 기사를 무작위 추출)을 받고 top-k 기사를 추천한다.(exploitation, exploration 둘 다 고려되어 만들어진 기사 리스트 L)
- FEEDBACK: 사용자가 기사 리스트(L)에 있는 각각의 아이템을 click or no click
- MINOR UPDATE: 각 timestamp에서 exploration network가 더 성능이 좋으면 다음 policy의 current network를 exploration하게 업데이트하고 exploitation network가 더 성능이 좋다면 그냥 둔다.
- MAJOR UPDATE: 특정 시간이 지나고 난 후, 사용자 feedback과 메모리에 저장 된 user activeness를 추가한다. (agent가 최근의 click, activeness 기록을 유지)
모델 이해한 흐름대로 설명하기
(offline, online dataset은 다름!)
1. offline part에서 학습 후 높은 score를 갖는 News List를 반환한다.
2. 한 유저에게 candidates라는 기사 셋을 네트워크에 보낸다.
3. 두 개의 모델에 같은 인풋을 적용한다.(push)
3.1. Current network라는 모델은 유저가 좋아할 것 같은 k개의 뉴스 리스트를 리턴하고,
3.2. Explore network 또한 똑같이 실행한다.
(여기서 Explore network는 current network 모델에서의 가중치 파라미터를 Gaussian Random Noise기법을 통해 업데이트한다. - 아래 Figure 7)
4. 두 모델에서 반환하는 리스트를 합쳐 유저의 reward가 발생할때까지 기다리고,
5. 유저의 reward feedback(click/no click)을 두 리스트들과 비교한다.
6. 만약, explore network의 성능이 더 높다면 다음 step의 current network 파라미터로 업데이트한다.(minor update)
7. 2~6 과정을 major update interval이 다가올때까지 반복한다.
(Major update 할 시기가 되었다.)
9. 위 반복되는 과정 속에서 user activeness에 대한 정보를 memory에 담아오고 있었다. 메모리에 있는 데이터(recent historical click & user activeness records) 중 batch size만큼 샘플링해서 모델을 업데이트한다.
10. 전체 흐름을 유저 수만큼 반복한다.(쉽게 말해서 Timeline의 t는 유저 한 명을 가리킨다.)





댓글