1장
# 임베딩의 역할
의미/문법 정보 함축(semantic/syntactic)
: 아들->딸 & 소년->소녀의 의미 차이가 임베딩에 함축되어 있으면 좋은 임베딩(word analogy test)
아들 + 딸 - 소녀 = 소년
# 임베딩 기법 역사
: 처음에는 단어 수준에서 임베딩을 진행했지만, 동음이의어의 경우 처리하기가 어렵다.
그래서 문장 수준에서의 임베딩으로 발전하게 되었다.(ELMo이후 BERT, GPT가 해당)
ex) 배(사람 배, 먹는 배, 타는 배)는 벡터 공간에서 같은 의미를 갖는 '배'끼리 가까이 존재한다.
(in detail)
룰 중심: 명사, 동사, 부사의 순서 지정
-> end-to-end: 딥러닝 모델이 인풋,아웃풋 사이의 관계 알아서 잘 근사 해주기 때문에 rule을 지정해주지 않아도 explainable(sequence-to-sequence 모델이 대표적)
-> pretrain/fine-tuning: 대규모 말뭉치로 임베딩하는데 이 임베딩에는 의미적, 문법적 맥락이 포함되어 있다.
# 임베딩 기법 종류
1. Matrix factorization
: 말뭉치 정보가 담긴 행렬을 두 개 이상의 작은 행렬로 쪼개는 것. 분해한 후에는 하나만 쓰거나 더하거나 concatenate해서 사용
ex) GloVe, Swivel
2. 예측 기반 방법
: 어떤 단어 주변에 특정 단어가 나타날지 예측하거나, 빈칸의 단어가 무엇일지 예측하는 것
ex) Word2Vec, FastText, BERT, ELMo, GPT
3. 토픽 기반 방법
: 주어진 문서에서 latent topic을 추론
ex)Latent Dirichlet Allocation(LDA)
2장
# 임베딩을 만드는 세 가지 철학
1. 어떤 단어가 많이 쓰였는가
1.1. Bag-of-words
: 어떤 단어가 (많이) 쓰였는가! 저자의 의도는 단어 사용 여부나 빈도에서 드러난다. 순서는 무시.
중복 원소를 허용한 집합
정보 검색에 많이 사용(질의&대상 문서 간 코사인 유사도를 통해 가장 높은 문서 노출)
1.2. TF-IDF
: TF(어떤 단어가 특정 문서에 얼마나 쓰였는지 빈도)
IDF(log(전체 문서 수 / 특정 단어가 나타난 문서의 수))
'를'과 같은 정보가 없는 단어들은 가중치가 0으로 줄어 불필요한 정보가 사라진다.
(if 전체 문서 수 == 특정 단어가 나타난 문서의 수, log(전자/후자) = 0)
1.3. Deep Averaging Network
: 문장 내에 어떤 단어가 쓰였는지, 얼마나 많이 쓰였는지의 빈도 파악 -> classification
2. 단어가 어떤 순서로 쓰였는가
Language Model
: 단어 시퀀스에 확률을 부여해 시퀀스 정보를 명시적으로 학습
2.1. 통계 기반 언어 모델
: MLE -> n-gram (직전 상태에만 의존하는 markov assumption에 기반)
2.2. 뉴럴 네트워크 기반 언어 모델
: 주어진 단어 시퀀스에서 다음 단어를 예측하는 과정에서 학습하는 ELMo나 GPT
문장 전체를 보고 중간 단어를 예측하는 과정에서 학습하는 모델인 BERT
3. 어떤. 단어가 같이 쓰였는가
3.1. Distributional Hypothesis
: 문장 내에서 어떤 단어가 같이 쓰였는지를 중요시 여긴다.
window 내에 동시에 등장하는 단어 쌍,pair(이웃 단어 또는 문맥의 집합)은 의미 또한 유사할 것이라는 가정
3.2. 형태소
: 계열 관계(paradigmatic relation) - 기존에 있던 형태소 자리에 다른 형태소가 와도 어색함 없이 대치될 수 있는지
3.3. 품사
: 기능 - 주어는 주어끼리, 동사는 동사끼리(언어학자들은 기능이 가장 중요한 측면이라고 말하기도 함)
의미 - 품사에 관계 없이 같은 의미를 내포하고 있는 단어끼리
형태 - 주어, 동사의 과거/현재/미래형과 같은 단어의 형태적 특성
4. Pointwise Mutual Information(PMI)
- 두 확률변수 사이의 상관성을 계량화하는 단위
- 두 확률변수가 완전히 독립이라면 값은 0이 된다.
- 독립이라는 것은 A 단어 이후 B 단어 등장에 전혀 영향을 주지 않는다는 뜻. 반대의 경우까지!(둘 다 영향주지 않는 것)
- PMI(A,B) = log( P(A,B)/P(A)XP(B) )
- word-context matrix에서 window 사이즈에 따라 타겟 단어 주변의 값을 +1 해주는 식으로 알고리즘 동작
5. Word2Vec
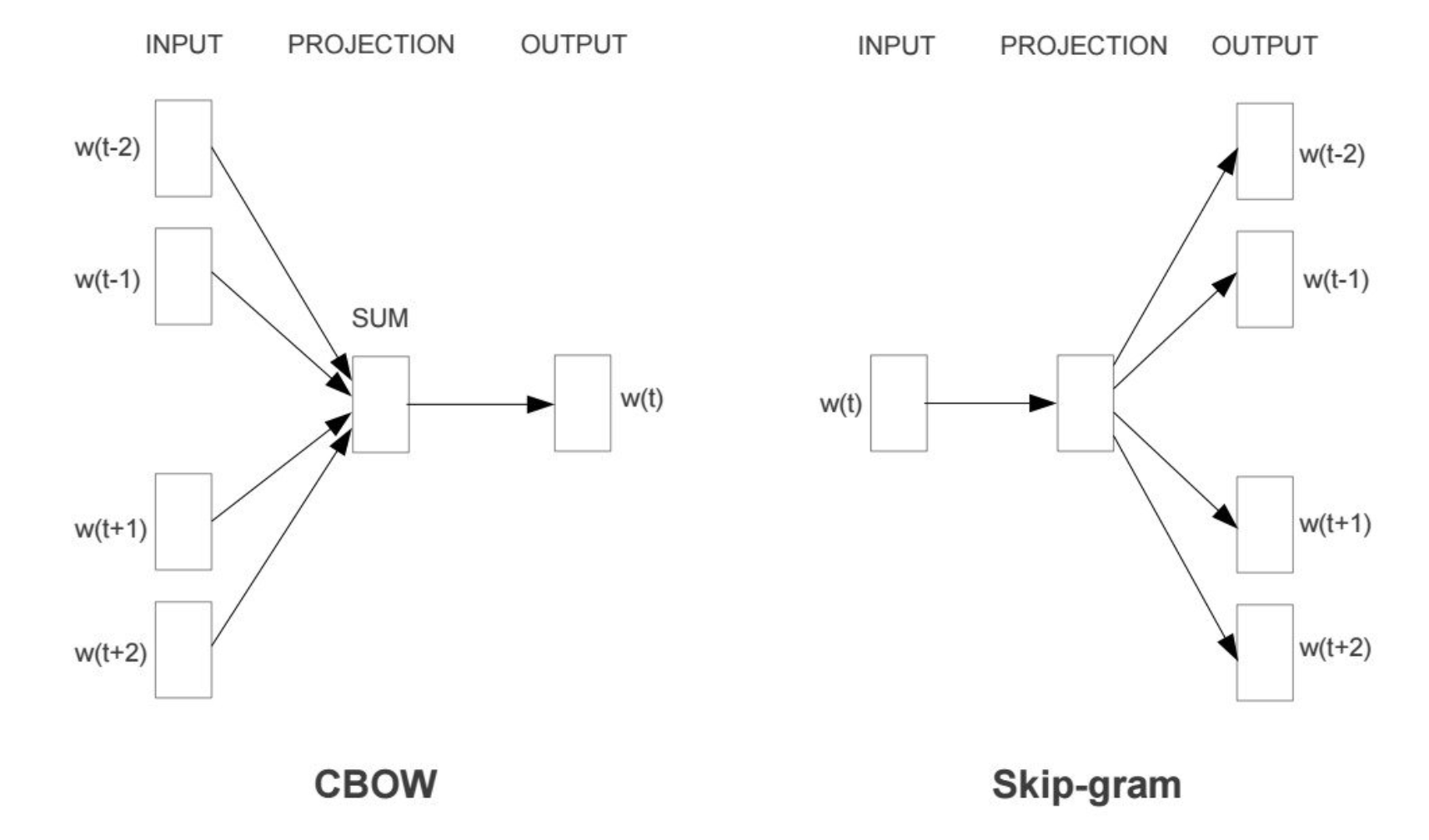
- CBOW(Continuous Bag-of-words): 주변 문맥 단어들로부터 중심 타겟 단어를 추론하는 기법
- Skip-gram: 타겟 단어를 가지고 주변 문맥 단어들을 추론하는 기법
4장
# 임베딩 모델
1. NPLM(Neural Probablistic Language Model)
: 문장이 말뭉치에 없어도 문맥이 비슷한 다른 문장을 참고해 확률을 부여 및 추론
1.1. 기존 LM의 한계
- 학습 데이터에 존재하지 않는 문장은 확률 값이 0이 됨
- 문장의 long-term dependency 포착 어려움(n-gram의 n은 5미만 - n이 커질수록 등장 확률이 0인 단어 시퀀스 기하급수적 증가)
- 단어/문장 간 유사도 계산 불가능
1.2. 모델
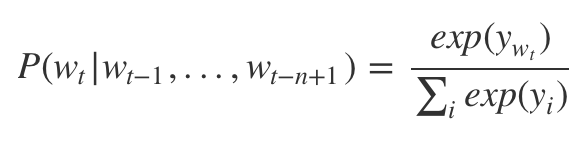
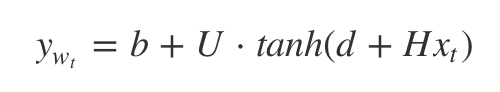
2. Word2Vec
: CBOW(Continuous Bag-of-words)와 Skip-gram 두 가지 모델이 있다.
Skip-gram은 아래 식을 최대화 하는 것이 목표이다
c: target word, o: context word

P(+|t,c) = 1 / (1 + exp(-u_t*v_c))
positive sample을 잘 뽑아내기 위해서는 'exp(-u_t*v_c)' 이 부분의 값을 낮춰야 한다.
이 말인 즉슨, 'u_t*v_c' 이 식에. 해당하는 내적 값을 키워야 한다는 것과 같다. 내적 값은 cosine similarity와 비례한다.

즉, 벡터간 유사도가 높으면 positive sample로 추출 될 확률이 높아진다.
- negative sampling: 오답이 덜 나오게 하기 위해 타겟 단어와 그 주변에 등장하지 않은 단어 쌍을 추출해낸다.
f(w_j)는 말뭉치에서 차지하는 비율(해당 단어 빈도/어휘 집합 크기)

P(-|t,c) = exp(-u_t*v_c) / (1 + exp(-u_t*v_c)) = 1 - P(+|t,c)
- subsampling: '은/는'과 같이 빈번하게 나오는 단어들 덜 학습 시키고,
나올 확률이 0에 가까운 단어들은 무조건 학습에 포함시키는 방법
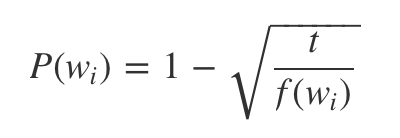
- Skip-gram 모델의 log-likelihood function
: positive sample 1 쌍과 negative sample k개 쌍을 한 번에 학습시킨다.
L(theta) = log( P(+|t,c) + (1~k)sigma(log(P(-|t,c)) ))
3. FastText
: 이 모델은 사용되는 전체 word를 character n-gram 형식으로 변환시킨 것 외에는 word2vec과 같다.
character 단위로 단어를 학습시키기 때문에 오타나 처음 보는 단어가 있어도 큰 문제가 생기지 않는다.
4. 잠재 의미 분석(Latent Semantic Analysis)
4.1. PPMI 행렬
: 원래 PMI 행렬은 두 단어가 독립일 때보다 확률이 낮을 때 음수가 되는 문제가 있어 0으로 치환해 무시하는 방법이다.
(*PMI: 두 확률변수 사이의 상관성을 계량화)
4.2. SVD(Singular Value Decomposition)
: 특이값 분해, 행렬 하나를 여러 개의 행렬로 나누어 표현해 잠재 된 의미를 분석하는 기법이다.
5. GloVe(Global Word Vector)
: 동시 등장 행렬을 분해(word-context matrix)
- 잠재 의미 분석의 문제점: corpus에 있는 모든 단어를 통계적으로 활용 가능하지만, 유사도 분석이 어렵다.
- Word2Vec의 문제점: 유사도 측정에는 유리하지만, 특정 window 사이즈 내에서만 학습이 가능해 corpus 전체 통계 정보 반영 어렵다.
=> 목적함수: 임베딩된 두 단어(target, context) 벡터의 내적이 corpus 전체에서의 동시 등장 빈도의 로그가 되도록 설정
6. Swivel(Submatrix-Wise Vector Embedding Learner)
: PMI 행렬을 분해
- 목적함수를 1. corpus에 한 번이라도 등장한 적 있는 것. 2. 없는 것 두 가지로 나눈다.
'AI > 공부' 카테고리의 다른 글
| [인과관계 추론] 9.Instrumental Variables (0) | 2021.08.06 |
|---|---|
| CNN (0) | 2019.09.30 |
| RNN & Automata (오토마타) (0) | 2019.09.24 |



댓글